 Skip to content
Skip to content
Remember when AI felt like a brilliant student who could answer instantly but sometimes got things spectacularly wrong? That era is shifting. The difference between traditional AI and reasoning models is like the difference between a quick guess and actually showing your work in math class. Welcome to the age where reasoning models AI are changing how we think about machine intelligence—not by making models bigger, but by giving them time to think.
For decades, we’ve been focused on parameter count—more is better, right? But the breakthrough with o1-class models isn’t about size. It’s about something more fundamental: deliberation. These models pause, consider, verify, and sometimes even correct themselves before responding. It’s a paradigm shift that’s making AI more reliable, more accurate, and frankly, more trustworthy for tasks that matter.
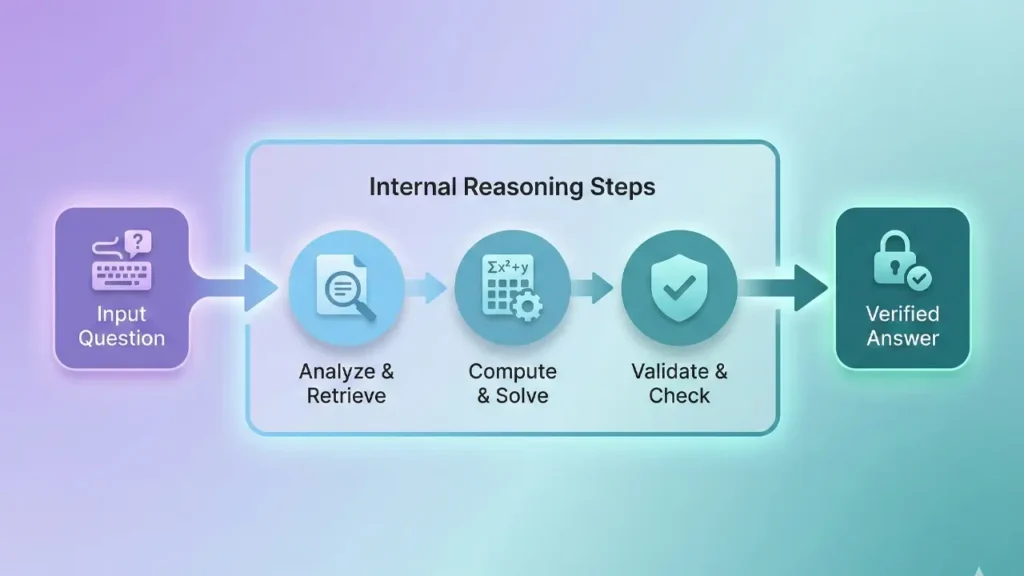
What Are Reasoning Models? Core Definition
At their heart, reasoning models represent a fundamental departure from traditional large language models. While standard LLMs predict the next token based on patterns learned during training, reasoning models engage in what we call chain of thought prompting—but it’s happening internally, automatically, and at scale.
Think of it this way: when you ask a traditional LLM a complex question, it immediately starts generating an answer, token by token, based on statistical patterns. It’s fast, often impressive, but fundamentally reactive. Reasoning models, on the other hand, generate an internal monologue first. They work through the problem step by step, exploring different approaches, identifying potential errors, and validating their reasoning before presenting you with a final answer.
This internal dialogue isn’t just for show. During training, these models learn to produce detailed reasoning traces that help them arrive at correct answers. The model literally learns that taking time to think through problems leads to better outcomes. OpenAI’s o1 model, for instance, uses reinforcement learning to optimize not just the final answer, but the entire reasoning process that leads to it.
The architecture enables something remarkable: self-correction. If the model notices an inconsistency in its reasoning, it can backtrack and try a different approach. It’s like having an internal peer review process happening in milliseconds.
How o1-Class Models Work: The Deliberation Process
The magic of o1-class models lies in their LLM deliberation process—a sophisticated dance of internal reasoning that happens before you see any output. Let me walk you through what’s actually happening under the hood.
When you submit a query to an o1-class model, it doesn’t rush to answer. Instead, it enters what researchers call a “thinking phase.” During this phase, the model generates what’s called a “chain of thought”—an extended internal monologue where it works through the problem systematically.
Here’s what makes this special: the model allocates different amounts of thinking time based on problem complexity. A simple question might get a few seconds of deliberation, while a complex mathematical proof could trigger minutes of internal reasoning. The model has learned through training that harder problems deserve more cognitive effort.
During deliberation, the model employs several key techniques. First, it breaks down complex problems into smaller, manageable steps. Second, it actively searches for potential errors in its reasoning. Third, it considers multiple solution paths before committing to one. Finally, it verifies its conclusions against the problem constraints.
The reinforcement learning component is crucial here. The model receives rewards not just for correct final answers, but for producing clear, logical reasoning chains that lead to those answers. Over time, it learns which reasoning strategies work best for different types of problems.
What’s particularly interesting is that this process is somewhat opaque—even to the developers. The model develops its own internal problem-solving strategies through training, much like how a human expert develops intuition. Sometimes researchers are surprised by the creative approaches these models discover.
Technical Breakdown: From Prediction to Reasoning
Understanding reasoning vs prediction models requires looking at how these systems process information fundamentally differently. Let me break down the key distinctions.
Traditional prediction models—what we typically call large language models—operate on a relatively straightforward principle. They’ve been trained on vast amounts of text and learned statistical patterns about which words tend to follow other words. When you ask a question, they generate a response by predicting the most likely next token, then the next, and so on. It’s remarkably effective for many tasks, but it has inherent limitations.
The problem with pure prediction is that it lacks verification. If a model predicts something that seems plausible based on its training data but happens to be incorrect, it has no mechanism to catch that error. It’s generating text that sounds right, not text that necessarily is right.
Reasoning models flip this script. Instead of immediately predicting an answer, they generate an internal reasoning trace first. This trace explores the problem space, considers different approaches, and validates conclusions before committing to a final output. The model isn’t just pattern-matching; it’s following logical steps.
The Intelligence Paradigm Shift
Quantifying the transition from high-speed token prediction to compute-intensive latent reasoning and self-verification.
| Architectural Aspect | Prediction Models (Standard) | Reasoning Models (o1/R1) |
|---|---|---|
| Response Logic | Immediate token prediction based on statistical probability. | Internal Monologue:
Hidden chain-of-thought processing prior to token output.
|
| Error Handling | Passive generation; limited capacity for real-time self-correction. |
Verification Loops
Built-in cross-check mechanisms for logical consistency.
|
| Compute Cost | Fixed / Low | Variable / High
Scales linearly with problem complexity.
|
| Strategic Utility | Fluency-focused: Creative writing, summaries, and general chat. | Logic-focused: Scientific research, math, coding, and accuracy-critical tasks. |
Fast, statistical token prediction.
Internal reasoning loops first, then output.
Creative writing & generic conversation.
Complex logic and accuracy-critical solving.
Scroll to compare more architectural aspects
The technical implementation involves training the model with reinforcement learning specifically optimized for reasoning tasks. The model learns to allocate computational resources strategically—spending more time on harder problems and less on simpler ones. This adaptive compute allocation is a key innovation that makes reasoning models practical.

Real-World Performance: Math & Logic Benchmarks
When we talk about AI math problem solving, the proof is in the benchmarks. And the results from reasoning models have been genuinely impressive, sometimes surpassing human expert performance on standardized tests.
Let’s start with GSM8K, a benchmark of grade school math problems that require multi-step reasoning. Traditional large language models hover around 60-70% accuracy on this benchmark. OpenAI’s o1 model? It achieves over 94% accuracy. That’s not just incremental improvement—it’s a qualitative leap in capability.
The MATH benchmark, which contains competition-level mathematics problems, tells an even more striking story. These problems often require advanced mathematical knowledge combined with creative problem-solving. While earlier models struggled to break 30% accuracy, o1 achieves over 83%. For context, the average human mathematician scores around 40% on this benchmark.
Perhaps most impressive is performance on Codeforces problems—programming challenges used in competitive coding competitions. O1 performs at approximately the 89th percentile of human competitors. It can analyze complex algorithmic problems, devise efficient solutions, and implement them correctly—tasks that require sustained logical reasoning.
The International Mathematics Olympiad (IMO) benchmark provides another data point. In 2024, reasoning models successfully solved problems that would challenge many professional mathematicians. While they didn’t achieve perfect scores, their performance represented a significant milestone in AI capability.
What’s driving these improvements? It’s the ability to show their work. When you examine the reasoning traces these models produce, you see them trying different approaches, catching arithmetic errors, and refining their solutions—much like a human expert would. The difference is they can do it faster and more consistently.
Case Study: DeepSeek R1 and Open-Source Reasoning
The story of DeepSeek R1 reasoning represents something important in AI development: the democratization of advanced reasoning capabilities. While companies like OpenAI and Google have pioneered reasoning models, DeepSeek has brought these capabilities to the open-source community.
DeepSeek R1, released in early 2025, demonstrated that reasoning model architecture isn’t the exclusive domain of well-funded labs. The model achieves competitive performance with commercial alternatives while being freely available for research and development. On mathematical reasoning benchmarks, R1 performs comparably to earlier versions of o1, solving complex problems through multi-step logical reasoning.
What makes DeepSeek R1 particularly interesting is its training approach. The team used distillation techniques, learning from the reasoning patterns of more capable models while developing its own problem-solving strategies. This resulted in a model that’s not just mimicking but genuinely reasoning through problems.
The model excels at tasks requiring sustained logical thought. In code generation, it doesn’t just predict plausible-looking code—it reasons about requirements, considers edge cases, and produces implementations that actually work. For scientific reasoning, it can follow multi-step arguments and identify logical inconsistencies.
The accessibility of R1 has accelerated research. Academic institutions that couldn’t afford expensive API calls to commercial reasoning models can now experiment with similar capabilities locally. Developers can fine-tune the model for domain-specific reasoning tasks. This open approach is fostering innovation across the field.
However, R1 also highlights the trade-offs inherent in reasoning models. It’s slower than traditional LLMs, requires more computational resources, and sometimes produces overly verbose explanations. But for tasks where accuracy matters more than speed, these trade-offs are often worthwhile.
Reducing Errors: How Reasoning Cuts Hallucinations
One of the most practical benefits of reasoning models is their role in reducing AI hallucinations reasoning—those confident but completely incorrect statements that plagued earlier AI systems. The mechanism behind this improvement is fascinating and multifaceted.
Traditional language models hallucinate because they’re trained to predict plausible text, not necessarily accurate text. If a model has learned that certain patterns of words frequently appear together, it will generate those patterns even when they describe something false. There’s no internal fact-checking mechanism.
Reasoning models address this through several key mechanisms. First, they engage in explicit verification. When the model makes a claim, it often checks that claim against its reasoning process. Does this conclusion follow logically from the premises? Are there any contradictions? This internal consistency checking catches many errors before they reach the output.
Second, reasoning models learn to express uncertainty appropriately. Through the training process, they discover that saying “I’m not certain, but here’s my reasoning” is often rewarded more than confidently stating incorrect information. This calibrated confidence is crucial for real-world applications.
Third, the step-by-step reasoning process creates an audit trail. When you can see how the model arrived at a conclusion, you can identify where reasoning went wrong. If the model claims something unsupported by its reasoning chain, that’s a red flag. This transparency makes errors more detectable, even when they slip through.
Research has shown significant reductions in hallucination rates for reasoning models compared to traditional LLMs on factual question-answering tasks. While they’re not perfect—no AI system is—the improvement is substantial and measurable.
The confidence scoring mechanisms in reasoning models are particularly sophisticated. Rather than assigning uniform confidence to all outputs, these models learn to be more confident about well-reasoned conclusions and less confident about speculative answers. This nuanced uncertainty representation helps users calibrate their trust appropriately.
Limitations & Trade-offs of Deliberative AI
While large reasoning models represent impressive technological progress, they come with real limitations that users and developers need to understand. Being honest about these trade-offs is essential for deploying these systems effectively.
The most obvious limitation is latency. Reasoning takes time—sometimes a lot of time. Where a standard LLM might respond in under a second, a reasoning model might think for 10, 30, or even 60 seconds on complex problems. For interactive applications where responsiveness matters, this delay can be unacceptable.
Cost is another significant factor. Because reasoning models perform substantially more computation per query, they’re more expensive to run. OpenAI’s o1, for example, costs significantly more per token than GPT-4. For applications processing millions of queries, these costs add up quickly.
There’s also the question of when reasoning is actually necessary. If you’re asking a model to write a friendly email or summarize a document, the deliberative capabilities of reasoning models are overkill. You’re paying for computational resources you don’t need. Standard LLMs handle these tasks perfectly well with better speed and cost efficiency.
Model Selection Framework
Determining the optimal compute-to-value ratio for diverse operational tasks, balancing speed against logical depth.
| Target Use Case | Standard Prediction LLM | Advanced Reasoning Model |
|---|---|---|
| Creative Writing | ✓ Excellent.
Optimal for narrative flow, speed, and low-cost generation.
|
Overkill; excessive latency for prose generation. |
| Mathematical Proofs | Higher risk of calculation errors and logical inconsistencies. | ✓ Superior.
High-fidelity verification of complex logical chains.
|
| Code: Simple Scripting | ✓ Recommended.
Sufficient for boilerplate, small functions, and unit tests.
|
Higher accuracy but unnecessary latency for simple tasks. |
| Complex Algorithm Design | Often produces “hallucinated” syntax or logic under pressure. | ✓ Reliable.
Deep architectural understanding and debugging logic.
|
| Casual Conversation | ✓ Optimal.
Low-latency, human-like responsiveness.
|
Unnecessary “thinking” delays interfere with chat flow. |
| Legal/Scientific Analysis | High risk of plausible but false data points (hallucination). | ✓ Trustworthy.
Built-in self-correction and cross-verification of data.
|
✓ Excellent & Fast.
Overkill; slower throughput.
Limited accuracy; risk of error.
✓ Superior Precision.
Scroll for complete architectural breakdown
The reasoning traces themselves can be verbose. Sometimes the model spends paragraphs working through logic that a human would process intuitively. While this transparency is valuable for verification, it can make interactions feel slower and more cumbersome than necessary.
There’s also a learning curve for users. Understanding when to deploy reasoning models versus standard LLMs requires judgment. Organizations need to develop guidelines for which tasks justify the additional cost and latency of reasoning models.
Finally, reasoning models aren’t immune to errors—they’re just better at avoiding certain types of mistakes. They can still struggle with knowledge gaps, ambiguous problems, or tasks requiring world knowledge beyond logical reasoning. Setting appropriate expectations is crucial.
Practical Applications: Where to Use Reasoning Models
Understanding where to implement AI logical reasoning can transform how organizations leverage AI. Let me walk you through the domains where reasoning models deliver the most value.
Code review and software development represent prime territory for reasoning models. When reviewing code, these models can follow logical flow, identify edge cases, spot potential bugs, and suggest improvements—all tasks requiring sustained analytical thinking. They don’t just pattern-match against common code structures; they reason about what the code actually does. Developers report that reasoning models catch subtle logic errors that traditional code analysis tools miss.
Scientific research and analysis benefit enormously from reasoning capabilities. Researchers can use these models to check mathematical derivations, identify flaws in experimental designs, or explore hypothetical scenarios. The model’s ability to work through multi-step logical arguments makes it a valuable research assistant. While it doesn’t replace human expertise, it serves as a tireless colleague willing to work through complex problems systematically.
Legal technology is another promising application. Contract analysis, for instance, requires understanding not just individual clauses but how they interact with each other and with relevant law. Reasoning models can identify potential conflicts, ambiguities, or unintended consequences in legal documents. Law firms are beginning to experiment with these capabilities for due diligence and contract review, though always with human oversight.
Education and tutoring represent perhaps the most exciting application. Reasoning models can work through problems step-by-step with students, identifying where understanding breaks down and providing targeted guidance. Unlike traditional AI tutors that might provide answers, reasoning models can engage in the pedagogical process—asking guiding questions, suggesting approaches, and helping students develop problem-solving skills.
Financial analysis and risk assessment leverage reasoning models’ ability to consider multiple factors simultaneously and work through complex scenarios. When evaluating investment opportunities or assessing risk, the model can systematically consider various factors, their interactions, and potential outcomes. This doesn’t replace human judgment but provides a structured analytical framework.
Medical diagnosis support is an emerging application, though one requiring extreme caution and human verification. Reasoning models can work through differential diagnoses, considering symptoms, test results, and medical history systematically. Their ability to catch potential oversights and consider rare conditions makes them valuable diagnostic aids, though never autonomous decision-makers.
Technical documentation and knowledge base creation benefit from reasoning models’ ability to organize information logically. They can take complex technical information and structure it in ways that reflect actual user needs and learning progression. The resulting documentation tends to be more logically coherent and easier to follow.
Future Outlook: The Road Beyond o1
Looking beyond current reasoning models AI, several trends are shaping the field’s evolution. The future isn’t just about making existing reasoning models better—it’s about fundamentally new architectures and capabilities.
Hybrid architectures represent one promising direction. Imagine systems that combine fast prediction for routine tasks with deep reasoning for complex problems, switching automatically based on query difficulty. These systems would give you the responsiveness of traditional LLMs when appropriate and the rigor of reasoning models when necessary. Early research in dynamic compute allocation suggests this is feasible.
Real-time reasoning is another frontier. Current reasoning models sacrifice speed for accuracy, but researchers are exploring ways to compress reasoning chains without losing their benefits. Techniques like distillation, where a faster model learns from a slower but more capable one, might enable reasoning-like capabilities with less latency. We’re already seeing models that deliver 80% of reasoning benefits at 50% of the cost.
The integration of reasoning with agentic workflows is particularly exciting. Imagine an AI agent that can not only take actions in the world but reason carefully about the consequences of those actions before proceeding. This combination of reasoning and agency could unlock new applications in autonomous systems, from software development to scientific experimentation.
Multimodal reasoning is expanding beyond text. Future models will reason about images, videos, and other data types with the same rigor they currently apply to text and code. A medical AI might reason through a diagnosis considering both imaging results and patient history. An engineering AI might reason about structural integrity while examining blueprints.
The democratization of reasoning capabilities will continue. As techniques mature and become better understood, smaller organizations and individual developers will gain access to these capabilities. Open-source models like DeepSeek R1 are just the beginning. We’ll likely see reasoning modules that can be added to existing models, much like how attention mechanisms spread across the field.
Interpretability and control will improve. Current reasoning models sometimes produce inscrutably long reasoning chains. Future systems will likely offer better controls over reasoning depth, style, and verbosity. Users might specify “explain your reasoning as if to a colleague” versus “just show the key logical steps.”
The convergence of different AI paradigms is perhaps most intriguing. Reasoning models might combine with retrieval systems, symbolic AI, and traditional machine learning in hybrid architectures that leverage the strengths of each approach. These multi-paradigm systems could be far more capable than any single approach.
Conclusion: Thinking Makes the Difference
The emergence of reasoning models marks a genuine inflection point in AI development. For too long, we’ve accepted that AI systems were brilliant but unreliable—incredibly knowledgeable but prone to confident errors. Reasoning models don’t solve this problem completely, but they represent substantial progress.
What makes reasoning models AI significant isn’t just their benchmark scores, though those are impressive. It’s the fundamental shift they represent in how we build intelligent systems. By giving models time to think, verify, and correct themselves, we’re creating AI that’s not just knowledgeable but thoughtful.
The practical implications are already becoming clear. Organizations deploying reasoning models for code review, scientific analysis, and other accuracy-critical tasks report fewer errors and more trustworthy outputs. Students working with reasoning-capable tutors develop better problem-solving skills. Researchers using these tools as thought partners make faster progress on complex problems.
But we’re still early in this journey. Current reasoning models are first-generation technology—impressive but with obvious limitations and room for improvement. The latency, cost, and occasional verbosity will improve. The applications we haven’t yet imagined will emerge as developers gain experience with these capabilities.
The key is matching the tool to the task. Not every problem needs deep reasoning, just as not every problem needs massive language models. But for tasks where accuracy matters, where errors are costly, where logical rigor is essential—reasoning models are changing what’s possible.
As these capabilities become more accessible through both commercial APIs and open-source alternatives, we’re likely to see reasoning become a standard component of AI systems. The question won’t be whether to use reasoning models but when and how to deploy them most effectively.
The future of AI isn’t just about making models bigger or faster. It’s about making them more thoughtful, more reliable, and more aligned with how humans actually solve complex problems. Reasoning models represent a significant step in that direction. The era of AI that thinks before it speaks has arrived, and it’s transforming what we can accomplish with artificial intelligence.
Love cutting-edge AI? Discover the hardware that powers innovation! From smart gadgets to tech accessories, explore the latest Chinese tech deals that complement your AI workflow. Upgrade your setup with affordable, high-performance devices. https://bestchinagadget.com/
Discover more from AI Innovation Hub
Subscribe to get the latest posts sent to your email.
