What Is GLM-5 Large Language Model?
Let’s start from the basics — because GLM-5 is one of those models that deserves a proper introduction.
GLM-5 is the fifth-generation large language model developed by Zhipu AI (Z.ai), a company founded in 2019 as a spin-off from one of China’s most prestigious institutions — Tsinghua University. If you’ve been following the AI space, you know that the competition between frontier models has never been more intense. And GLM-5 steps into this arena with something remarkable to say.
GLM-5 represents a generational leap in AI capability, featuring approximately 745 billion total parameters in a Mixture of Experts (MoE) architecture. It is engineered from the ground up for agentic intelligence, advanced multi-step reasoning, and frontier-level performance across coding, creative writing, and complex problem-solving.
What makes this model particularly noteworthy isn’t just its raw scale. It’s the story behind it — a Chinese AI lab, built on academic roots, creating a model that competes with OpenAI and Anthropic, trained entirely without Western hardware. That’s a headline in itself.
Whether you’re a developer, a product manager, or just an AI enthusiast trying to understand what’s happening in the global AI race, GLM-5 is worth your attention. Let’s break it down piece by piece.
2. GLM-5 AI Model: Core Concept
At its heart, GLM-5 is designed around one central philosophy: scaling intelligence, not just parameters.
Zhipu AI’s approach with the GLM family has always been to build models that are genuinely useful in production — not just impressive on leaderboards. With GLM-5, the team pushed this philosophy further, targeting what they call “agentic engineering” — the ability of an AI to carry out complex, multi-step tasks autonomously, like a skilled engineer rather than a simple text generator.
GLM-5 shifts the paradigm from coding to engineering, demonstrating strong deep-reasoning performance in backend architecture, complex algorithms, and stubborn bug fixing. It directly benchmarks against Claude Opus 4.5 in code-logic density and systems-engineering capability.
What does that mean in practice? Think of it this way: earlier AI models could write a function or explain a concept. GLM-5 is built to architect entire systems, debug deeply nested logic, and execute long-horizon workflows — all with minimal human handholding.
Zhipu AI completed a landmark Hong Kong IPO on January 8, 2026, raising approximately HKD 4.35 billion (USD $558 million) — funding that has directly accelerated GLM-5’s development and positioned Zhipu AI for sustained investment in next-generation AI architectures.
This institutional momentum is important context. GLM-5 isn’t a side project. It’s the flagship product of a publicly listed company with serious capital behind it.
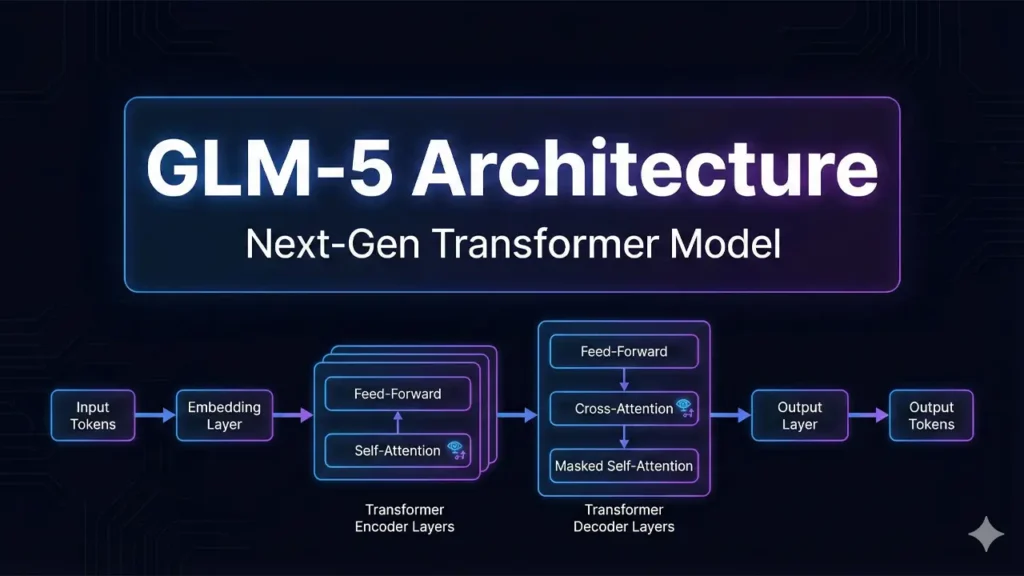
3. GLM-5 Architecture Explained
Now let’s get into the mechanics — but we’ll keep it friendly, promise.
GLM-5 uses a Mixture of Experts (MoE) architecture. Here’s the key insight: instead of activating all 745 billion parameters for every token it processes, the model selectively “wakes up” only a subset of its expert networks. This makes inference dramatically more efficient.
GLM-5 uses a Transformer decoder with Mixture-of-Experts (MoE) structure — 78 layers, 256 experts per layer with 8 activated, yielding approximately 44 billion active parameters at 5.9% sparsity. The first three layers are dense; subsequent layers use DeepSeek-style Sparse Attention (DSA).
Think of it like a consulting firm: the firm employs 256 specialists, but for any given client problem, only 8 are called in. The result is deep expertise applied efficiently — not 256 generalists talking over each other.
GLM-5 integrates DeepSeek Sparse Attention (DSA), largely reducing deployment cost while preserving long-context capacity. Compared to GLM-4.5, GLM-5 scales from 355B parameters (32B active) to 744B parameters (40B active), and increases pre-training data from 23T to 28.5T tokens.
Another architectural highlight: Multi-Token Prediction. GLM-5 AI employs Multi-Token Prediction for faster inference — predicting multiple tokens per forward pass, reducing latency while maintaining output quality. Combined with DSA, this delivers 2x throughput over traditional autoregressive decoding.
And then there’s the context window. GLM-5 supports up to 200,000 input tokens and 128,000 output tokens — meaning it can process entire codebases, lengthy research papers, or complex legal documents in a single session without losing coherence.
One more architectural milestone worth noting: GLM-5 was trained entirely on Huawei Ascend chips using the MindSpore framework, achieving full independence from US-manufactured hardware. This isn’t just a geopolitical statement — it’s a genuine technical achievement in hardware-software co-optimization.
4. GLM-5 Capabilities and Strengths
So what can GLM-5 actually do? Let’s walk through the core capability pillars.
Advanced Reasoning. GLM-5 achieves frontier-level multi-step logical reasoning and complex problem-solving, enabling it to tackle mathematical proofs, scientific analysis, and intricate analytical tasks.
Code Generation & Engineering. GLM-5 generates, debugs, and refactors code across 50+ programming languages. This includes not just syntax-level code generation but architectural-level thinking — understanding how components interact in large systems.
Agentic Task Execution. A core differentiator of GLM-5 is its built-in agentic architecture — designed for autonomous planning, tool utilization, web browsing, and multi-step workflow management with minimal human intervention.
Long-Context Understanding. GLM-5 handles massive context windows, enabling it to process and reason over extensive documents, research papers, codebases, and even video transcripts in a single session.
Creative and Generative Writing. GLM-5 generates high-quality, nuanced creative content with stylistic versatility — from long-form narrative and technical documentation to marketing copy and academic prose.
Multilingual Support. GLM-5 AI supports native English, Chinese, and 15+ additional languages with leading multilingual performance.

5. GLM-5 Performance Benchmark Results
Numbers tell the story. Here’s how GLM-5 performs across major industry benchmarks, based on officially reported data:
GLM-5 Performance Intelligence Matrix
Strategic audit of frontier intelligence capabilities across reasoning, software engineering, and expert knowledge domains.
| Benchmark Cluster | Measured Score | Measured Intelligence Domain |
|---|---|---|
| Software Engineering SWE-bench Verified |
77.8% SOTA Capability |
Autonomous resolution of real-world GitHub issues and repository maintenance. |
| Programming HumanEval |
90.0% | Zero-shot Python code generation accuracy across discrete functional tasks. |
| Programming LiveCodeBench |
88.0% | Competitive programming performance on unseen, real-time platform updates. |
| Math Reasoning GSM8K |
97.0% | Grade-school word problem multi-step arithmetic reasoning. |
| Math Reasoning MATH |
88.0% | Advanced multi-domain mathematical problem solving and logic. |
| Advanced Logic AIME 2025 |
84.0% Top Tier | Highly complex Invitational Math Examination benchmarks (American context). |
| Hard Sciences GPQA (Graduate) |
68.2% | PhD-level reasoning across Biology, Physics, and Chemistry (Google/OpenAI standard). |
| General Knowledge MMLU / MMLU Pro |
85.0% / 70.4% | Professional and academic multi-subject knowledge across 57 distinct disciplines. |
| Extreme Reasoning Humanity’s Last Exam |
50.4% With Tool Use |
High-complexity, cross-domain expert reasoning (HLE benchmark). |
GLM-5 achieved the highest performance among open-weights models on Artificial Analysis’ Intelligence Index, τ²-Bench Telecom, Vending Bench 2, and Chatbot Arena Code.
In Vending Bench 2, a benchmark for long-term operational capabilities, GLM-5 achieved an account balance of $4,432 USD, ranking it first among all open-source models.
These numbers position GLM-5 not just as a Chinese model — but as a genuinely global-tier open-source system.
6. GLM-5 vs GPT-4: Real Comparison
This is the comparison everyone wants to see. Let’s be fair and factual.
First, context: GPT-4 is now a previous-generation model. The current OpenAI flagship is GPT-5 (or GPT-4o/4.5 in API form). But GPT-4 remains a common industry baseline, so the comparison is still instructive.
Frontier Intelligence Matrix
Strategic audit comparing open-weight Mixture-of-Experts (GLM-5) vs. proprietary dense scaling architectures (GPT-4).
| Dimension | GLM-5 (Zhipu AI) | GPT-4 / Turbo (OpenAI) |
|---|---|---|
| Architecture | MoE: 745B Total / 44B Active Sparsely activated Mixture of Experts. |
Dense Transformer (~1T-1.8T) Speculated high-scale dense architecture. |
| Open Source | MIT License ✓ Full Weight Transparency. |
Proprietary ✕ Closed Weights / SaaS Only. |
| Context Flow | 200K Input / 128K Output | 128K Window (GPT-4 Turbo) |
| Agentic Native | Native Logic Architected for intrinsic tool manipulation. |
Middleware Logic Implemented via function calling/plugins. |
| Inference ROI | ~$1.00 / M tokens High-efficiency MoE economics. |
$10.00 – $30.00 / M tokens Managed cloud premium margins. |
| Sovereignty | ✓ Full Local Deployment. Supports vLLM, SGLang. |
✕ Cloud SaaS Dependencies. |
| Hardware Stack | Huawei Ascend (MindSpore Native). Regional silicon optimization. |
NVIDIA H100/H200 Optimized. Global datacenter standard. |
| Software Eng. | 77.8% (SWE-bench) Expert-level issue resolution. |
~54.0% (GPT-4 Turbo) Generalist coding support. |
The bottom line: GLM-5 outperforms GPT-4 on key coding benchmarks, offers a far larger context window, is open-source, and costs significantly less per API token. Where GPT-4 still holds an edge is in brand trust, Western infrastructure support, and the broader OpenAI ecosystem (fine-tuning tools, documentation depth, developer community size).
For teams prioritizing cost efficiency, open deployment, and coding performance — GLM-5 is genuinely competitive. For teams deeply integrated into the OpenAI stack, switching has friction that goes beyond benchmark scores.
7. GLM-5 Multimodal Model Potential
Is GLM-5 purely a text model? Not quite — and this is where the roadmap gets interesting.
Z.ai has launched GLM-Image, a state-of-the-art image generation model built on a multimodal architecture and fully trained on domestic chips, combining autoregressive semantic understanding with diffusion-based decoding to deliver high-quality, controllable visual generation.
Within the broader GLM ecosystem, vision-language models are an active focus. GLM-4.6V enhances vision understanding, achieving state-of-the-art performance in tasks involving images and text, with a context window of 128K for efficient processing of long multimodal inputs.
The GLM-5 ecosystem includes Seedream 5.0 for photorealistic 2K image generation — covering text-to-image, image editing, and multi-subject composition.
There’s also a speech layer forming: GLM-ASR-2512 delivers industry-leading accuracy with a Character Error Rate of just 0.0717, with significantly improved performance across real-world multilingual and accent-rich scenarios.
So while GLM-5 itself is primarily a text and code model, Z.ai is building a full multimodal stack around it. Think of GLM-5 as the reasoning engine — with vision, speech, and image generation modules being integrated as surrounding layers.
This modular multimodal architecture is a smart approach: it allows the core language model to remain focused and optimized while specialist models handle other modalities at high quality.
8. GLM-5 Use Cases for Business
Let’s get practical. Where does GLM-5 actually add value in a business context?
Software Development & Engineering. This is GLM-5’s strongest suit. Development teams can use it to accelerate backend architecture design, automate code review, write tests, fix complex bugs, and handle legacy code migration. On τ²-Bench, which evaluates interactive tool use, GLM-4.7 (the preceding model) achieves a score of 87.4, the highest reported result among publicly available open-source models — with GLM-5 continuing this trajectory.
Finance & Data Analysis. The model’s long-context capability (200K tokens) makes it ideal for processing large financial documents, earnings reports, or regulatory filings. Its reasoning layer supports multi-step analysis that would normally require a human analyst.
Customer Support Automation. GLM-5’s agentic design means it can handle multi-turn customer interactions, escalate when appropriate, and integrate with CRM tools through function calling — going beyond simple chatbots.
SaaS & Product Automation. For SaaS companies, GLM-5’s tool-use capabilities allow it to operate within existing platforms, automate workflows, and generate structured outputs like reports, summaries, and product documentation.
E-Commerce. Product description generation, multilingual support for global markets, customer query handling, and personalized recommendations all fall within GLM-5’s capability envelope.
Legal & Compliance. Long-document understanding makes GLM-5 well-suited for processing contracts, regulations, and compliance documents — surfacing relevant clauses, flagging inconsistencies, and drafting summaries.
The enterprise appeal here is real: open weights mean data stays on your infrastructure, pricing is competitive, and the agentic architecture reduces the need for human-in-the-loop at every step.

9. GLM-5 API Access and Integration
How do you actually use GLM-5? There are several paths.
Web Interface. Users can use the model through the Z.ai chat platform in chat mode or agent mode. This is the fastest way to get started — no setup required.
API Access. The API is available at $1.00/$0.20/$3.20 per million input/cached/output tokens, with coding-focused plans ranging from $27 to $216 per quarter. Access is provided through Z.ai’s API platform at api.z.ai and BigModel.cn.
Open Weights for Local Deployment. This is where GLM-5 differentiates significantly from proprietary alternatives. vLLM, SGLang, KTransformers, and xLLM all support local deployment of GLM-5, with model weights publicly available on Hugging Face and ModelScope under the MIT license.
Hardware Compatibility. Zhipu AI supports GLM-5 on multiple non-NVIDIA chips, including Moore Threads, Cambricon, Kunlun Chip, MetaX, Enflame, and Hygon — achieving appropriate throughput through kernel optimization and model quantization.
Integration Considerations. For Western enterprise teams, a few practical realities apply. The primary API platform and documentation are hosted by a Chinese company, which raises data governance questions for regulated industries. Teams in the EU or US handling sensitive data should evaluate whether local deployment (using open weights) is a better fit than the cloud API. That said, the MIT license is permissive and commercially friendly — there are no restrictions on building products on top of GLM-5.
For developers already comfortable with LLM integrations, the API format follows standard conventions. Function calling, reasoning modes, and context caching are all supported — making integration with existing pipelines relatively straightforward.
10. Final Verdict: Is GLM-5 Large Language Model the Future?
Let’s be direct.
GLM-5 is not “just another Chinese AI model.” It is a frontier-tier, open-source system that competes with proprietary heavyweights on several meaningful dimensions — coding performance, long-context reasoning, and agentic task execution being the most compelling.
GLM-5 topped other open-weights models in Artificial Analysis’ Intelligence Index and achieved best-in-class results among open-source systems on multiple coding and agentic benchmarks.
The open-source MIT licensing is a genuine competitive advantage. It means organizations can deploy it locally, inspect the weights, fine-tune for domain-specific use cases, and avoid per-token API costs at scale. That’s a compelling offer for enterprise teams that have privacy requirements or want to own their AI stack.
The hardware independence story also matters: GLM-5’s training entirely on Huawei Ascend chips represents a milestone in China’s effort toward a self-reliant AI infrastructure — and signals that the global AI hardware ecosystem is becoming more pluralistic, not less.
Who should seriously consider GLM-5?
Development teams looking for a cost-efficient, open-source alternative to GPT-4 or Claude for code-heavy workflows will find it immediately valuable. Research teams that need long-context document processing. Startups building AI-native products who want to avoid proprietary lock-in. Enterprises in Asia already aligned with Zhipu AI’s ecosystem.
Who should proceed with caution?
Organizations in highly regulated Western industries where provenance and data governance around Chinese AI infrastructure are under scrutiny. Teams whose workflows depend on the full OpenAI or Anthropic toolchain (fine-tuning APIs, safety tooling, partner integrations). Anyone prioritizing multimodal capabilities as a core requirement today rather than 12–18 months from now.
The honest forecast: GLM-5 marks a clear inflection point in the global open-source AI landscape. The center of gravity in open-weights AI has shifted decisively eastward, with Chinese developers responsible for a succession of leading open-weights models including GLM-5, Kimi K2, Qwen3-VL, and Kimi K2.5.
This isn’t hype — it’s a structural shift. GLM-5 is proof that frontier AI is no longer the exclusive domain of Silicon Valley. For organizations willing to engage with it thoughtfully, it offers genuine value today. For the rest of us watching the space — this is the model that tells you the 2026 AI competition just got a lot more interesting.
AI models like GLM-5 are transforming software — but innovation doesn’t stop there. Hardware is evolving just as fast. If you’re curious how advanced manufacturing meets smart automation, explore cutting-edge 3D printing technologies at https://bestchina3dprinters.com/ and discover what’s shaping the next generation of production.
Discover more from AI Innovation Hub
Subscribe to get the latest posts sent to your email.
You could certainly see your enthusiasm within the article you write.
The arena hopes for more passionate writers such as you who aren’t afraid
to mention how they believe. Always go after your heart.