NVIDIA GB200 NVL72: 7 Powerful Insights into the Rack-Scale AI Super-GPU
Introduction: The Dawn of the AI Factory
The relentless march of artificial intelligence has hit an inflection point. We are no longer merely training models on curated datasets; we are entering the era of continuous learning, real-time generation, and industrial-scale AI deployment. This new paradigm demands a new kind of computational infrastructure—one that is not just powerful, but monolithic, efficient, and purpose-built. Enter the NVIDIA GB200 NVL72, the cornerstone of what NVIDIA CEO Jensen Huang has termed the “AI Factory.”
The NVIDIA GB200 NVL72 is not just another GPU. It is a fundamental re-architecture of high-performance computing for the generative AI age. It represents a shift from server-scale to rack-scale design, treating an entire data center rack as a single, colossal computing entity. This system is engineered with one primary goal: to serve and scale the world’s most demanding AI workloads, specifically the trillion-parameter large language models (LLMs) and foundation models that are reshaping industries.
In this comprehensive analysis from aiinnovationhub.com, we will deconstruct the GB200 NVL72 through seven powerful insights. We will move beyond the marketing headlines and delve into the architectural marvels, the tangible performance claims like the 30x inference speed boost, the revolutionary NVLink Switch System, and the very real manufacturing and physical constraints—the HBM3E / CoWoS bottlenecks—that will define its impact on the future of enterprise AI infrastructure. This is not just a product launch; it is a blueprint for the next decade of AI.

Insight 1: Deconstructing the GB200 NVL72 – What Exactly Is It?
Before we can appreciate its capabilities, we must first understand its composition. The NVIDIA GB200 NVL72 is a complex, hierarchical system. Let’s break it down from the silicon up.
The Building Blocks: Grace CPU and Blackwell GPU
At the most fundamental level is the NVIDIA Blackwell GB200 superchip. This is not a single piece of silicon but a tightly integrated pair:
- Grace CPU: NVIDIA’s own ARM-based server CPU. It’s designed not for raw compute but for extreme efficiency in feeding data to the GPU. With its high core count, massive LPDDR5x memory bandwidth, and low power consumption, the Grace CPU acts as the perfect “orchestrator” for the Blackwell GPU, ensuring it is never starved of data.
- Blackwell GPU: This is the heart of the system. The B200 GPU is a monumental leap over its Hopper predecessor (H100). It boasts:
- 208 Billion Transistors: Fabricated on a custom 4NP TSMC process.
- Second-Generation Transformer Engine: Hardware and software designed to accelerate the core components of LLMs, dynamically managing FP4 and FP6 precision formats to double AI performance.
- Fifth-Generation NVLink: Providing 1.8 TB/s of bidirectional bandwidth between just two GPUs, which is crucial for model parallelism.
The GB200 superchip combines one Grace CPU and two B200 GPUs into a single, coherent module, connected by a 900 GB/s chip-to-chip link. This eliminates the traditional PCIe bottleneck between CPU and GPU, creating a unified computing powerhouse.
The NVL72 Rack-Scale System: A Single “Super-GPU”
The “NVL72” in the name reveals the system’s ultimate scale. It is a liquid-cooled rack that integrates:
- 36 x GB200 Superchips. Since each superchip contains 2 B200 GPUs, this gives us a total of 72 B200 GPUs and 36 Grace CPUs in a single rack.
- A Unified Memory and Compute Fabric: This is the true magic. Through a next-generation NVLink Switch System, all 72 GPUs are interconnected with a staggering 130 TB/s of all-to-all bandwidth. This effectively unifies the HBM3E memory across all GPUs, creating a single, massive pool of shared memory.
In essence, the GB200 NVL72 presents itself to software as a single compute node with the combined power of 72 top-tier GPUs. This architectural paradigm is what enables it to run trillion-parameter models that would be impossible to fit into the memory of a single server.
www.aiinnovationhub.shop (review AI-tools for business): «Enter, choose ready scenarios – save hours on startup».
Mini-review on www.aiinovationhub.com: «Quick reviews without words – it is convenient to start from scratch».
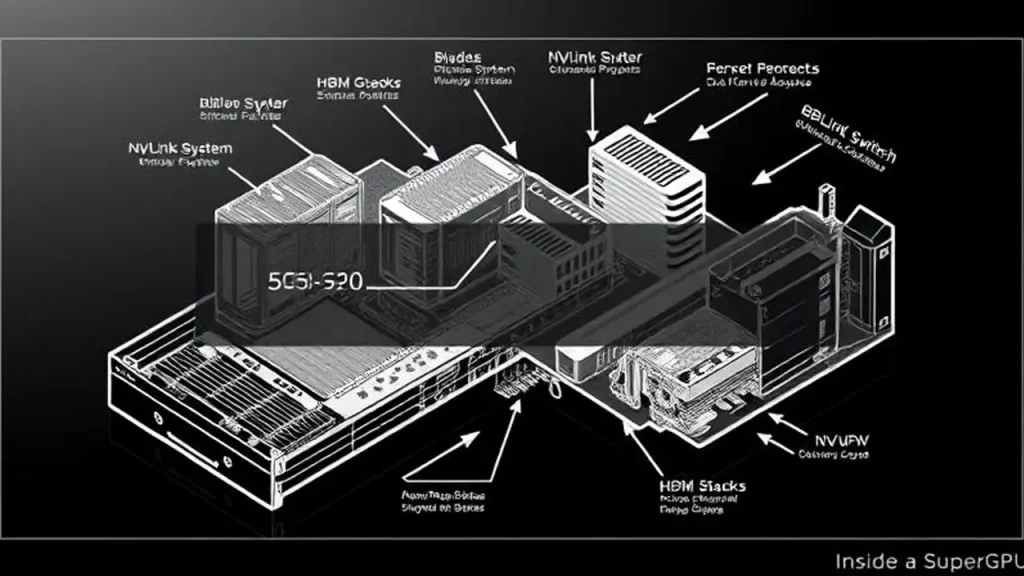
Insight 2: The Architectural Masterstroke – The NVLink Switch System
The single most significant innovation in the NVIDIA GB200 NVL72 is arguably the NVLink Switch System. To understand why, we must first acknowledge the problem it solves: communication bottlenecks.
In traditional multi-GPU systems, even with NVLink, GPUs are grouped in small pods (e.g., 8 GPUs). Communication between these pods happens over slower, higher-latency network fabrics like InfiniBand or Ethernet. For a trillion-parameter model, where different layers of the neural network are split across hundreds of GPUs, this inter-pod communication becomes the dominant bottleneck, crippling performance.
The NVLink Switch System obliterates this bottleneck. It is a dedicated, high-radix switch chip that allows every GPU in the rack to communicate with every other GPU at the full, blistering speed of NVLink. With 130 TB/s of bisectional bandwidth, it creates a seamless, unified fabric.
The Implication for AI Factories: This means that data scientists and engineers can develop and deploy models as if they have a single, gigantic GPU at their disposal. They no longer need to spend months on complex model-parallelism strategies to work around network limitations. The NVLink Switch System abstracts away the physical complexity of the rack, enabling a software-defined approach to enterprise AI infrastructure where the entire system is a programmable resource.

Insight 3: The Performance Promise – Unpacking the “30x Inference Speed” Claim
NVIDIA’s claim of a 30x inference speed increase for the GB200 NVL72 over a single H100 GPU for LLMs like GPT-3 175B is audacious. How is this possible? It’s not one single improvement but a combination of several, working in concert:
- Raw Compute & Speculative Execution: The Blackwell architecture introduces a novel feature called “Speculative Decoding.” For inference, a large, powerful model (like the one running on the 72 GPUs) can be assisted by a smaller, faster draft model. The large model validates the draft model’s output in parallel, dramatically reducing the number of steps required to generate a full response. This alone can account for a significant portion of the speedup.
- Second-Gen Transformer Engine: By leveraging FP4 and FP6 precision natively, the Blackwell GPUs can perform more operations per second and fit larger model segments into the same HBM memory, reducing the need for costly memory swapping.
- The Unified Fabric: The NVLink Switch System ensures that during inference, there is virtually no communication overhead between the GPUs hosting the model. The entire inference process happens at the speed of the chip’s internal fabric, not the external network.
- Massive Model Fit: Perhaps most importantly, the entire trillion-parameter model can reside within the unified HBM of the rack. There is no need to offload parts of the model to slower CPU or SSD memory, which is a massive performance killer in disaggregated systems.
This 30x inference speed isn’t just about faster answers; it’s about making previously impossible applications feasible. Real-time, complex agentic AI, interactive video generation, and scientific simulation at scale become tangible realities with this level of performance.

Insight 4: Conquering the Trillion-Parameter Frontier
Why is the ability to handle trillion-parameter LLM inference such a big deal? The trend in AI has been clear: larger models, trained on more data, demonstrate emergent capabilities, better reasoning, and higher accuracy. However, deploying these behemoths has been a nightmare of distributed computing.
The GB200 NVL72 is the first system architected from the ground up to not just train but, more importantly, to serve these models efficiently. Serving a model for inference requires low latency and high throughput, which is much harder than the batch-oriented process of training.
By providing a unified memory space measured in terabytes and a communication fabric with terabytes per second of bandwidth, the NVL72 allows a 1-trillion parameter model (which requires approximately 2 TB of GPU memory in FP16 precision) to be loaded and run seamlessly. This “Rack-scale super GPU” approach effectively future-proofs enterprise AI infrastructure for the next generation of foundation models, ensuring that businesses can deploy state-of-the-art AI without being hamstrung by their hardware.

Insight 5: The Physical Realities – HBM3E and CoWoS Bottlenecks
For all its digital brilliance, the NVIDIA GB200 NVL72 is constrained by the physical world. Two terms have become central to the discourse around advanced AI chips: HBM3E and CoWoS. These represent the most critical bottlenecks in the global AI supply chain.
- HBM3E (High-Bandwidth Memory 3E): This is the latest standard of memory stacks that are vertically integrated on top of the GPU silicon using a technology called 2.5D packaging. HBM is essential because it provides the massive bandwidth needed to feed the ravenous compute cores of a GPU. Without it, the GPU would sit idle, waiting for data. The B200 GPU uses advanced HBM3E, but its production is complex, expensive, and capacity-constrained, primarily supplied by SK Hynix and Samsung.
- CoWoS (Chip-on-Wafer-on-Substrate): This is TSMC’s proprietary packaging technology that allows the large B200 GPU die and its multiple HBM3E stacks to be connected on a single interposer. This packaging is what creates the “superchip.” The demand for CoWoS packaging has exploded, and TSMC’s production capacity is a primary limiter for how many NVIDIA Blackwell GB200 chips can be built.
The GB200 NVL72, with its 72 GPUs, represents an unprecedented concentration of these constrained resources. A single rack consumes a significant portion of the global advanced packaging and HBM output. This reality means that:
- Availability will be limited and costly. Only the largest cloud providers and enterprises will have initial access.
- It reinforces NVIDIA’s moat. Competitors cannot simply design a rival chip; they must also navigate the same extreme supply chain challenges, which NVIDIA has spent years and billions of dollars securing.
Understanding these HBM3E / CoWoS bottlenecks is crucial for any enterprise planning its AI roadmap, as it directly impacts availability, timing, and total cost of ownership.
Insight 6: The Software Ecosystem – The Invisible Engine
Hardware is useless without software. The GB200 NVL72 is not a standalone product; it is the ultimate expression of NVIDIA’s full-stack strategy. It is designed to be programmed with NVIDIA’s CUDA and its higher-level libraries like NVIDIA NIM microservices and frameworks like NeMo.
Because the system appears as a single node, developers can use familiar tools and APIs. The complexity of managing 72 GPUs is handled by the system’s firmware and software stack. This seamless integration is a powerful competitive advantage, ensuring that the vast ecosystem of AI developers building on NVIDIA technology can immediately leverage the power of the NVL72 with minimal code changes.
Insight 7: The Strategic Implication – Redefining Enterprise AI Infrastructure
The arrival of the GB200 NVL72 is more than a technical milestone; it’s a strategic earthquake. It concretizes the concept of the AI factory—a dedicated, turnkey facility where data is the raw material and intelligence is the finished product.
For enterprises, this signals a shift in how they must think about their AI investments:
- From CapEx to OpEx: The extreme cost and rapid evolution of this hardware will push more companies towards a cloud-based, “AI-as-a-Service” model from providers who operate these racks.
- The Rise of Sovereign AI: Nations and large corporations may invest in their own AI factories based on systems like the NVL72 to ensure data sovereignty and control over their strategic AI assets.
- A New Competitive Divide: Access to and mastery of this level of computational infrastructure will create a significant divide between AI “haves” and “have-nots.” Companies that can leverage this power will innovate and automate at a pace others cannot match.
The NVIDIA GB200 NVL72 is not just a product for today’s AI models; it is an infrastructure built for the AI models of 2027 and beyond. It sets a new benchmark, forcing the entire industry—from chip designers to cloud providers—to respond.
Conclusion: The Blackwell Legacy – A New Compute Paradigm
The NVIDIA GB200 NVL72 is a testament to vertical innovation. It is a system where the architecture of the silicon, the module, the node, and the rack are all co-designed to serve a singular, monumental task: scaling generative AI to its physical limits.
Through its rack-scale super GPU design, revolutionary NVLink Switch System, and promise of 30x inference speed for trillion-parameter LLMs, it offers a glimpse into the future of high-performance computing. While challenges like HBM3E / CoWoS bottlenecks will dictate its initial rollout, its architectural principles will undoubtedly trickle down and influence the entire landscape of enterprise AI infrastructure for years to come.
The era of the AI factory has begun, and the NVIDIA GB200 NVL72 is its defining engine. The question for businesses is no longer if they will engage with this scale of computing, but how and when.
Meet the next wave of AI infrastructure: NVIDIA GB200 NVL72. Think rack-scale “super-GPU” built for AI factories—30× faster inference, NVLink Switch fabric, and cooling engineered for trillion-parameter LLMs. In our new breakdown, we explain what this means for startups, cloud teams, and enterprise IT: cost per token, throughput per rack, and how HBM/CoWoS supply can still be a bottleneck. Plain language, no fluff—just the essentials you can use in planning.
Read the full post: https://aiinovationhub.com/nvidia-gb200-nvl72-30x-aiinnovationhub-com/
If you’re choosing tools or building roadmaps, save our site—aiinovationhub.com—for weekly deep dives and simple, actionable checklists.
#NVIDIA #GB200 #NVL72 #AIFactories #LLM #Inference #NVLink #HBM #Blackwell #aiinnovationhub
Встречайте следующую волну AI-инфры: NVIDIA GB200 NVL72. Это rack-scale «супер-GPU» для AI-фабрик — заявленное ускорение инференса до 30×, коммутируемая шина NVLink и охлаждение под LLM с триллионом параметров. В новом разборе мы простыми словами объясняем, что это значит для стартапов, облаков и энтерпрайза: стоимость за токен, производительность стойки и почему поставки HBM/CoWoS всё ещё узкое горлышко. Никакой «воды» — только то, что поможет в планировании.
Читать полностью: https://aiinovationhub.com/nvidia-gb200-nvl72-30x-aiinnovationhub-com/
Если выбираете инструменты или строите дорожную карту — добавьте aiinovationhub.com в закладки: каждую неделю там практичные разборы и чек-листы.
#NVIDIA #GB200 #NVL72 #AIфабрики #LLM #Инференс #NVLink #HBM #Blackwell #aiinnovationhub
Discover more from AI Innovation Hub
Subscribe to get the latest posts sent to your email.
Pingback: Changan UNI-K 2.0 turbo 4x4 — Outstanding AWD
Pingback: aiinnovationhub.com: GPT-5 vs Gemini 2.5 — 7 Epic Wins