1. Introduction: Why MoE vs Dense Model Cost Efficiency Matters
If you have been following the AI industry over the past few years, you already know that MoE vs Dense Model Cost Efficiency is no longer just an academic question — it is one of the most pressing topics in real-world AI deployment. Training and running large language models costs millions of dollars, and those costs are climbing as models grow larger and more capable. For companies building AI-powered products, the difference between a smart architectural choice and a poor one can mean the difference between a profitable service and an unsustainable infrastructure bill.
AI compute optimization has become the central challenge for teams working with frontier models. Engineers, researchers, and product leaders are all asking the same question: how do we get maximum intelligence per dollar spent? That question is precisely what makes the comparison between Mixture-of-Experts (MoE) and dense model architectures so important today.
In this guide, we will walk through both architectures in plain language, compare their real-world costs, and explore how newer concepts like agentic AI memory architecture are changing the picture even further. Whether you are a developer, a business leader evaluating AI vendors, or simply a curious reader who wants to understand what is happening inside the models powering today’s AI products, this article is for you.
2. What Is a Dense Model in Modern AI
To understand the MoE vs Dense Model debate, we need to start with the baseline: the dense model. When people talk about dense neural networks, they mean architectures where every single parameter in the model participates in processing every single token that passes through the network. GPT-2, GPT-3, LLaMA, and early versions of many other large language models follow this design philosophy.
In a dense transformer model, the architecture consists of stacked layers of attention mechanisms and feed-forward networks. For every token the model processes, the computation flows through all layers and all neurons in those layers — no shortcuts, no selective activation. This design is conceptually clean and relatively straightforward to train, which is one of the reasons it dominated the first generation of large language models.
However, the computational cost of this approach scales in a challenging way. As you add more parameters to a dense model to improve its capabilities, you also proportionally increase the compute required for every single forward pass during inference. A model with 70 billion parameters requires roughly twice the floating point operations per token compared to a 35 billion parameter model — every time, for every user, for every query.
When exploring dense vs sparse AI models, this “always-on” characteristic of dense architectures is the key differentiator. Dense models are reliable and well-understood, but their cost scales linearly (or worse) with parameter count, which creates real economic pressure as you try to make models smarter.
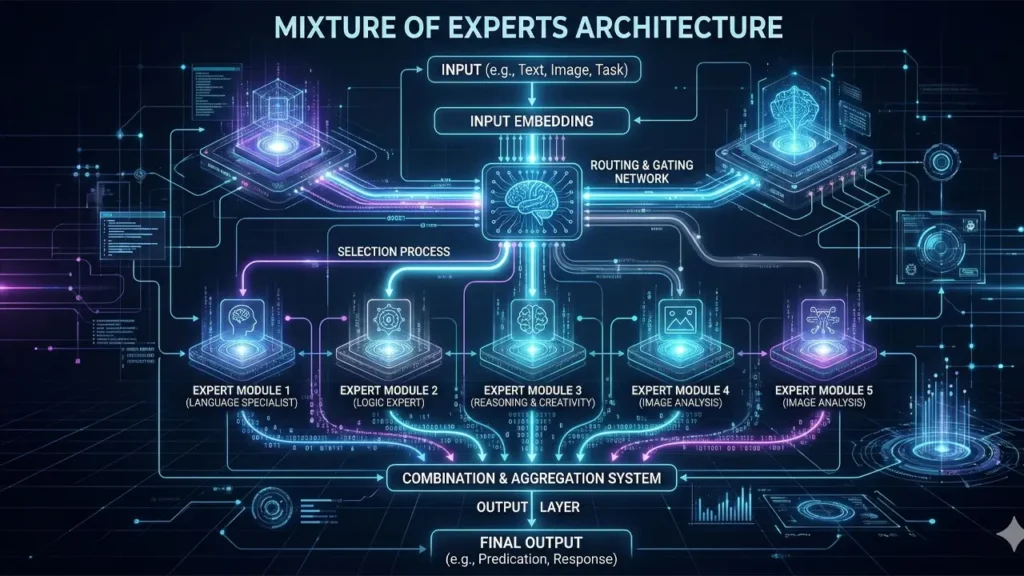
3. Understanding Mixture of Experts Architecture
Now let’s look at the other side of the mixture of experts vs dense model comparison. Mixture-of-Experts (MoE) is not a new idea — it was first formally described in a 1991 paper by Jacobs, Jordan, Nowlan, and Hinton — but it has seen a major renaissance in modern large language model design, particularly in models like Google’s Gemini 1.5, Mistral’s Mixtral 8x7B, and the architecture underlying DeepSeek’s recent releases.
The core idea of MoE is elegant: instead of using all the model’s parameters for every token, you divide the feed-forward layers of the network into a collection of specialized sub-networks called experts. Alongside these experts, you have a lightweight routing component called a gating network (sometimes called a router). For each token that enters an MoE layer, the gating network decides which experts — typically just 1 or 2 out of a pool that might contain 8, 16, or even 64 experts — should process that token.
The result is a model that can have a very large total parameter count while only activating a small fraction of those parameters for any given computation. A model might have 47 billion total parameters, but only activate around 13 billion parameters per token — achieving the reasoning quality of a larger model at the inference cost of a smaller one.
This selective activation is the fundamental mechanism that makes MoE architectures so interesting from a cost perspective. The gating network learns, during training, to route different types of content to different experts, effectively allowing the model to develop specializations. Some experts may become better at handling mathematical reasoning, others at language translation, and others at code generation — all within a single unified model.
4. MoE vs Dense Model Cost Efficiency in Real Deployments
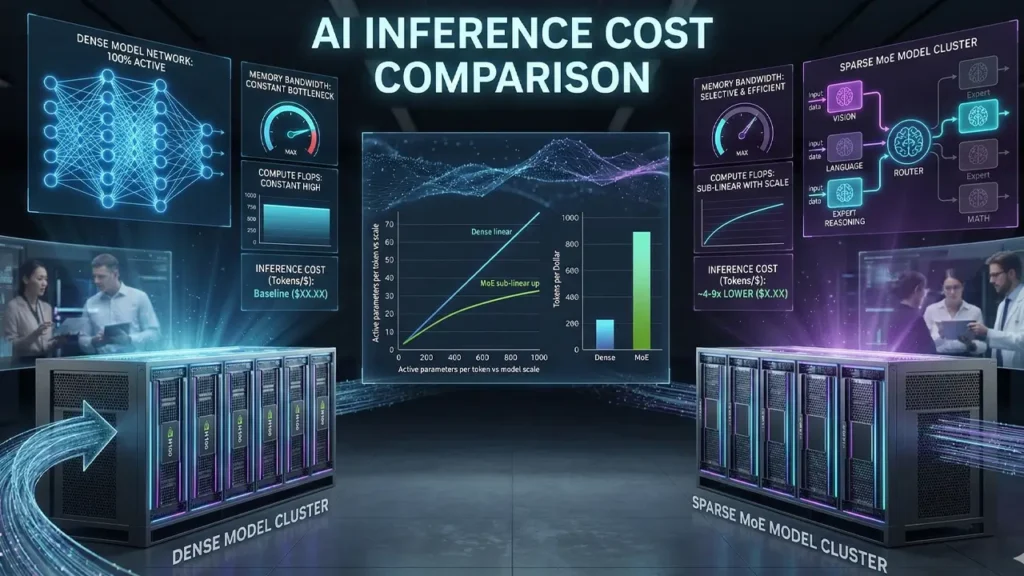
Let’s get concrete. When comparing MoE vs Dense Model Cost Efficiency in actual production deployments, there are two separate cost dimensions to consider: training cost and inference cost.
Training cost for MoE models is more complex. Because all experts need to be trained, and because training requires careful load balancing (to prevent the gating network from routing everything to just one or two popular experts), MoE models generally require more sophisticated training infrastructure and longer training runs compared to a dense model with equivalent active parameters. However, compared to a dense model with equivalent total parameters, MoE training is significantly cheaper.
Inference cost is where MoE really shines in the AI inference cost comparison. Since only a subset of parameters activates per token, the memory bandwidth requirements and FLOP count per forward pass are dramatically lower than a dense model of equivalent total size. This translates directly to lower GPU utilization per query, faster response times, and lower cost per million tokens at the serving layer.
Dense vs. Mixture-of-Experts
A strategic audit of inference throughput, infrastructure overhead, and the financial delta between static and sparse model architectures.
| Operational Metric | Dense Architecture | MoE (Sparse) Architecture |
|---|---|---|
| Activation |
100% of Total Params
Full weights engaged per token.
|
~20–30% of Total Params
Efficiency Lead
|
| Throughput |
High Compute Intensity
Scales linearly with parameter count.
|
Significantly Lower FLOPs
Decoupled intelligence from compute.
|
| Complexity | Standard Baseline
Predictable gradient descent.
|
Higher Latent Risk
Requires complex load balancing.
|
| VRAM Usage |
Proportional to Active Params
|
All-Expert Persistence
Requires significant VRAM pooling.
|
| Economics |
Higher Marginal Cost
|
Lower Marginal Cost
Enables sub-dollar inference.
|
100% Parameter Engagement
20-30% Active Expert Routing
Scroll for detailed VRAM and Distributed Infrastructure audit
One important nuance: while MoE models save on compute per token, they still require all expert parameters to be loaded into GPU memory, even if only a few are active at any moment. This means MoE models can have a larger total memory footprint despite their lower compute requirements. Organizations deploying MoE at scale need to account for this memory overhead in their hardware planning.
5. Sparse Transformer Architecture Explained
The sparse transformer architecture is the broader family within which MoE sits. Sparsity, in the context of AI, refers to the property of only activating a subset of the network’s components for any given input. This is directly opposed to the “dense” approach where everything is always active.
Sparse architectures reduce GPU consumption through a simple but powerful mechanism: if you do not compute something, you do not pay for it. In a standard dense transformer, every layer performs matrix multiplications across the full parameter space for every token. In a sparse transformer, operations are conditionally skipped based on routing decisions made at runtime.
Beyond MoE, sparsity also appears in attention mechanisms. Standard “full” attention has quadratic complexity with respect to sequence length — meaning doubling the context window quadruples the attention computation. Sparse attention patterns, such as those used in Longformer and BigBird architectures from Google Research, address this by limiting attention to local windows and global summary tokens, dramatically reducing the cost of processing long documents.
The combination of sparse attention and sparse feed-forward layers (MoE) is a powerful recipe for building models that can handle both long contexts and large parameter counts without the runaway costs that would otherwise make such models impractical. This is why sparse transformer architecture has become a central pillar of modern frontier model design.
When you hear researchers discussing the efficiency gains in next-generation models, sparse transformer design decisions are almost always a major part of the explanation.
6. AI Model Scaling Strategies for Large Language Models
One of the most important frameworks in AI research is the concept of scaling laws — empirical relationships between model size, training data volume, compute budget, and model performance. Understanding AI model scaling strategies is essential context for the MoE vs dense comparison.
The original Chinchilla scaling laws, published by researchers at DeepMind in 2022, showed that many large language models were significantly undertrained — they had too many parameters for the amount of data they were trained on. The implication was that a smaller model, trained on more data, could match or exceed a larger, undertrained model at lower cost.
MoE architectures interact with scaling laws in an interesting way. Because MoE models have a large total parameter count but a much smaller “active” parameter count, they effectively decouple two dimensions that were previously linked in dense models: the model’s capacity (total parameters) and its per-token compute cost (active parameters). This decoupling gives researchers a new lever to pull when designing systems.
Practically, AI model scaling strategies for MoE include:
- Increasing the number of experts while keeping the number of active experts per token constant — this increases model capacity cheaply
- Expert parallelism — distributing different experts across different GPUs or even different machines, so the memory footprint per device remains manageable
- Hierarchical MoE — using multiple layers of routing for even finer-grained specialization
- Combining MoE with quantization — reducing the precision of stored weights to further decrease memory requirements
These strategies have allowed teams at Google, Mistral AI, and other labs to build models with hundreds of billions of total parameters that can still serve responses efficiently and at competitive cost.
7. Agentic AI Memory Architecture Best Practices
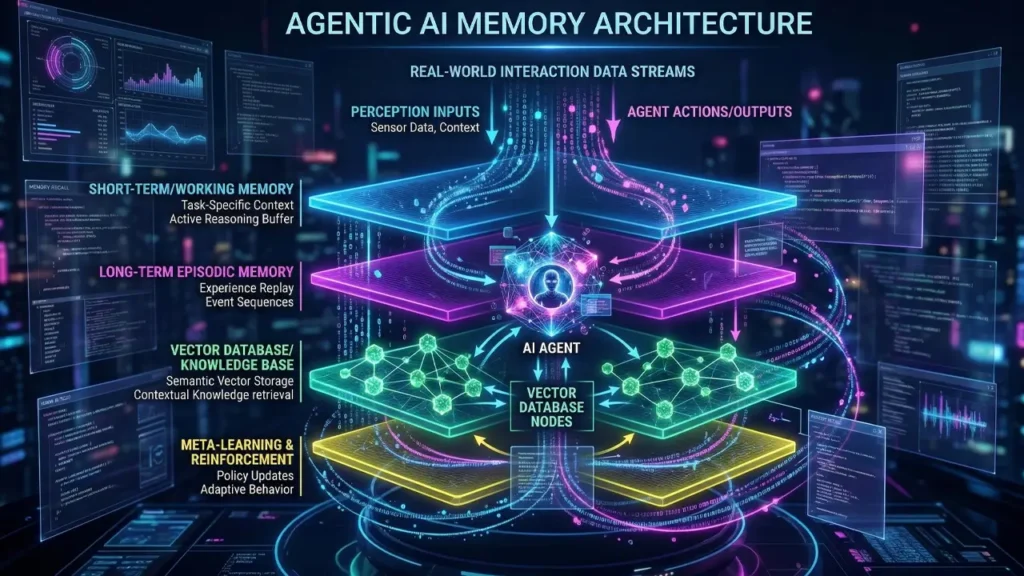
As AI systems evolve from simple chatbots to complex autonomous agents that can plan, execute multi-step tasks, and maintain context across long interactions, agentic AI memory architecture has become a critical design consideration.
A language model on its own has no persistent memory — every new conversation starts from scratch. But agentic systems need to remember: what tasks have been completed, what was learned in previous sessions, what the user’s long-term goals are, and what facts are relevant to the current context. This is where memory architecture comes in.
Modern agentic systems typically combine several memory layers:
In-context memory is the simplest form — information stored directly in the model’s active context window. This is fast and immediately accessible but is limited by context length and disappears when the session ends.
External vector memory uses embedding models to convert information into high-dimensional vectors, which are stored in a vector database (such as Pinecone, Weaviate, or pgvector). When the agent needs to retrieve relevant information, it performs a similarity search against this database, pulling in semantically relevant memories dynamically. This approach scales well and enables long-term memory across sessions.
Episodic storage maintains structured logs of past interactions, task outcomes, and decisions. Unlike raw vector memory, episodic storage preserves temporal and causal relationships, allowing agents to reason about sequences of events (e.g., “last time I tried approach X, it failed for reason Y, so this time I should try Z”).
Parametric memory — the knowledge baked into the model’s weights during training — is also technically a form of memory, though it cannot be updated at runtime without fine-tuning.
Cognitive Memory Matrix
Mapping the hierarchy of AI data persistence, from high-speed in-context reasoning to the permanent parametric embedding of world knowledge.
| Memory Modality | Persistence | Retrieval Latency | Optimal Use Case |
|---|---|---|---|
|
In-Context
|
Session-Only |
INSTANT
|
Short-term reasoning and dynamic instruction following.
|
|
Vector (RAG)
|
Long-Term |
FAST (ms)
|
Large-scale semantic knowledge and document retrieval.
|
|
Episodic
|
Long-Term |
MODERATE
|
User task history, interaction logs, and agent planning.
|
|
Parametric
|
Immutable* |
INSTANT
|
Foundational world knowledge and inherent linguistic skills.
|
Vector (RAG)
Best for semantic retrieval across massive external datasets and corporate knowledge bases.
Parametric
The base world knowledge stored directly in the model weights via pre-training.
Audit covers 4 foundational cognitive tiers
For MoE-based agents, the interaction between memory architecture and model architecture is particularly interesting. MoE models with their expert specialization are theoretically well-suited to benefit from rich external memory — different experts can specialize in reasoning over different memory types, potentially improving retrieval and synthesis quality.
8. Cost Efficiency of Large Language Models in Production
When evaluating the cost efficiency of large language models in a production cloud environment, several factors come into play beyond just the architecture choice.
Major cloud providers — including Google Cloud (Vertex AI), Amazon Web Services (Bedrock), and Microsoft Azure (Azure OpenAI Service) — all offer API access to frontier models at per-token pricing. As of publicly available pricing data, costs typically range from under $1 to over $15 per million tokens depending on the model and whether you are measuring input or output tokens.
MoE-based models tend to appear at the more affordable end of this spectrum for equivalent capability levels. Mistral AI’s Mixtral 8x7B, for instance, has been widely noted in the research community as delivering benchmark performance comparable to models with significantly higher dense parameter counts, at a fraction of the serving cost.
For enterprises running high-volume workloads — millions to billions of tokens per day — the architectural choice directly determines infrastructure spend. Consider a simplified scenario:
Inference Economics Matrix
Analyzing the daily operational expenditure (OpEx) delta between dense transformer architectures and high-efficiency sparse MoE models across scaling tiers.
| Scaling Scenario | Daily Throughput | Dense Model Cost | MoE Model Cost (Est.) |
|---|---|---|---|
| Emerging Tier
Small SaaS
|
10M Tokens
|
~$150.00
|
~$50.00 — $80.00
50% Avg. Savings
|
| Growth Tier
Mid-Size Enterprise
|
500M Tokens
|
~$7,500.00
|
~$2,500 — $4,000
2.5x ROI
|
| Hyperscale Tier
Large Platform
|
5B Tokens
|
~$75,000.00
|
~$25K — $40K
$35K+ Daily Delta
|
Large Platform
5B Daily Token Volume
Enterprise
500M Daily Token Volume
Scroll for detailed sub-10M token economics
Note: These are illustrative estimates for comparison purposes based on publicly discussed pricing ranges. Actual costs vary by provider, model, and negotiated agreements.
These numbers make it immediately clear why the industry has moved so aggressively toward MoE and sparse architectures. The potential savings are not marginal — they can be transformative for unit economics.
9. MoE Model Efficiency: Advantages and Limitations
No technology is perfect, and MoE model efficiency comes with a genuine set of trade-offs that any serious practitioner needs to understand.
Advantages of MoE models:
The most obvious advantage is the inference cost reduction we have already discussed. But there are other benefits too. MoE models can, in theory, achieve better sample efficiency during training — a larger total capacity means the model has more “room” to specialize, potentially learning from training data more effectively per token seen. Additionally, the modular nature of MoE architectures makes them conceptually appealing for future research into model interpretability and targeted fine-tuning of specific expert subsets.
Limitations and challenges:
The biggest practical challenge with MoE models is memory requirements at serving time. While active compute is low, all expert weights must typically reside in GPU memory (or at least be rapidly accessible) to avoid latency spikes. A model with 8 experts that are each 7 billion parameters in size needs to have all 47+ billion parameters in memory, even though only ~13 billion are used per token. For organizations running on limited GPU budgets, this can be a significant barrier.
Load balancing during training is another known difficulty. If the gating network consistently routes too many tokens to the same experts and ignores others, the underutilized experts fail to train properly — a phenomenon called expert collapse. Researchers have developed auxiliary loss functions and other techniques to combat this, but it adds complexity to the training process.
Latency variability can also be higher in MoE systems, particularly in distributed deployments where different experts live on different machines. Network communication overhead between expert servers can introduce unpredictable delays depending on which experts are selected for a given batch of tokens.
Finally, debugging and interpretability are more complex in MoE systems. When a model gives an unexpected output, it can be harder to trace the cause when the computation was distributed across dynamically selected expert networks.
10. Final Verdict: The Future of MoE vs Dense Model Cost Efficiency
After walking through both architectures in depth, the picture for MoE vs Dense Model Cost Efficiency becomes clear: MoE has moved from an academic curiosity to a production-proven approach that is now central to how the most capable and cost-efficient models are being built.
The evidence is compelling. Google’s Gemini 1.5 Pro, one of the most capable multimodal models available, is widely reported to use an MoE architecture. Mistral AI demonstrated with Mixtral that an open-source MoE model could compete with much larger dense models on standard benchmarks. DeepSeek’s releases have further validated that MoE-based designs can achieve frontier-level performance at dramatically lower inference costs than equivalent dense alternatives.
For the future, the trajectory seems clear: as models grow larger and use cases more demanding, the industry will increasingly rely on MoE and other sparse architectural patterns to manage the economics of large-scale AI deployment. The question is not really “MoE or dense?” for most frontier applications — it is “how do we implement MoE most effectively for our specific use case?”
The practical guidance:
When comparing large language model architecture comparison options for your organization, consider the following decision framework:
- If you are running high-volume inference workloads and cost is a primary concern, MoE-based models offer compelling advantages
- If you are working with constrained GPU memory environments (edge deployment, small clusters), dense models may actually be more practical despite their higher per-token compute
- If you are building agentic systems with complex memory requirements, the architecture choice should be evaluated alongside your memory architecture design — the two interact significantly
- If you are evaluating cloud API providers, compare not just price-per-token but model capability-to-cost ratios, since MoE-based models often deliver better value on this composite metric
The broader lesson from the MoE vs dense debate is that AI architecture is not a static field. The same researchers who validated dense scaling laws are now building the MoE systems that improve upon them. Staying current with these architectural developments is not optional for anyone building serious AI-powered products — it is a competitive necessity.
For ongoing analysis of AI model architectures, cost efficiency trends, and emerging research in large language model design, explore the in-depth coverage at www.aiinovationhub.com, where we track these developments as they unfold.
BestChina3DPrinters
Expert Reviews & Rankings
Independent 3D Printer Reviews
Your trusted source for Chinese 3D printer reviews, rankings, and comparisons. We buy, test, and review every printer so you can make informed decisions.
Discover more from AI Innovation Hub
Subscribe to get the latest posts sent to your email.