Imagine having a single AI model that can read text from images, detect objects, describe scenes, and segment visual elements—all without sending data to the cloud. That’s exactly what the Florence-2 computer vision model brings to the table. In a world where privacy concerns are mounting and real-time processing matters more than ever, this unified vision foundation model from Microsoft is changing how developers approach computer vision tasks. Whether you’re building a robotics system, a mobile app, or an edge device solution, Florence-2’s prompt-based approach eliminates the need to juggle multiple specialized models. Let’s dive into why this all-in-one vision model is gaining traction and how you can leverage it for your projects.

What the Model Is and Why Microsoft Released It
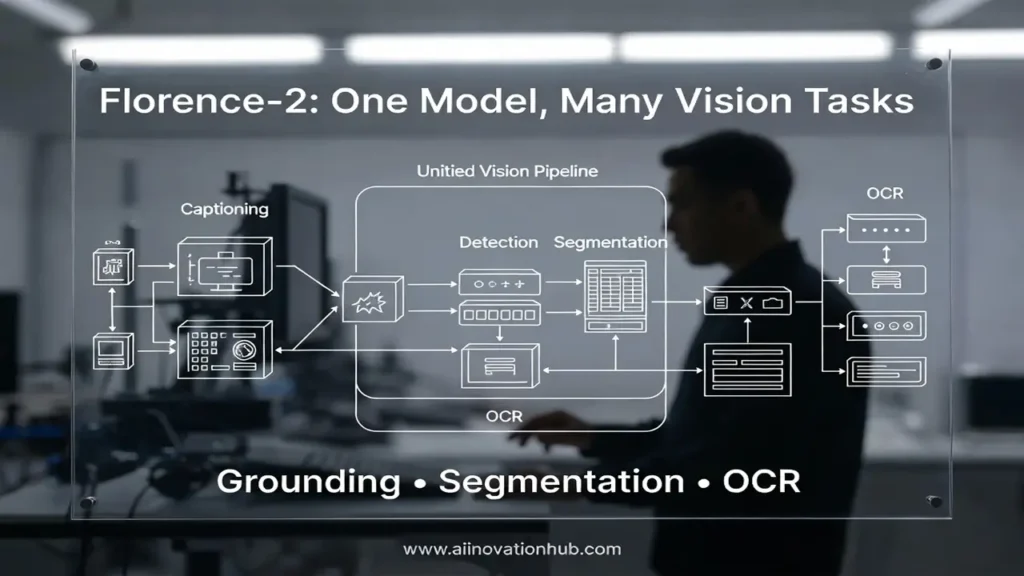
The Microsoft Florence-2 model represents a significant shift in computer vision architecture. Unlike traditional approaches that require separate models for each task—one for object detection, another for OCR, yet another for segmentation—Florence-2 is a vision-language model (VLM) that handles multiple vision tasks through a unified prompt-based interface.
Microsoft designed Florence-2 as a vision foundation model, meaning it’s built on a broad base of visual understanding that can be adapted to various downstream tasks. The key innovation here is the prompt-based paradigm: you simply tell the model what you want using natural language or task-specific prompts, and it responds accordingly. Want to detect cars in an image? Prompt it. Need to read text from a receipt? Same model, different prompt.
Why did Microsoft pursue this unified approach? The answer lies in efficiency and practicality. In real-world applications, you often need multiple vision capabilities working together. A warehouse robot might need to read package labels (OCR), detect obstacles (object detection), and understand spatial relationships (visual grounding) simultaneously. Running three separate models means triple the computational overhead, complexity in integration, and potential synchronization issues. Florence-2 solves this by consolidating these capabilities into a single, coherent architecture.
The model comes in different sizes to accommodate various deployment scenarios, from resource-constrained edge devices to more powerful systems. This flexibility makes the Florence-2 computer vision model accessible whether you’re running inference on a smartphone, a Raspberry Pi, or a GPU-equipped server.
Reading Text from Images
One of Florence-2’s standout capabilities is Florence-2 OCR (Optical Character Recognition). This functionality goes beyond simple text detection—it can accurately extract text from complex real-world scenarios where traditional OCR systems struggle.
Consider practical applications: automated document processing where invoices and receipts need to be digitized instantly, retail environments where price tags and product labels must be read by smart shelves or inventory robots, manufacturing floors where equipment interfaces and serial numbers need to be logged automatically. The Florence-2 computer vision model handles all these scenarios with a single prompt interface.
What makes Florence-2’s OCR particularly valuable is its contextual understanding. Because it’s a vision-language model, it doesn’t just recognize individual characters—it understands text in the context of the surrounding image. This means better accuracy when dealing with challenging conditions like varying fonts, rotated text, low contrast, or text embedded in complex backgrounds.
For robotics applications, this is transformative. Imagine a warehouse robot that needs to read barcodes, shipping labels, and safety warnings on packages. With Florence-2 OCR, the robot can process all these text elements using the same model that’s also handling navigation and object manipulation tasks. This integration reduces the computational load and simplifies the software stack.
Mobile app developers also benefit significantly. Building accessibility features for visually impaired users becomes more straightforward when you can extract text from any image—restaurant menus, street signs, product packaging—all processed locally on the device without sending sensitive data to cloud servers.
Finding and Localizing Objects
Florence-2 object detection brings robust object localization capabilities to the unified model framework. When you need to know not just what’s in an image, but precisely where each object is located, Florence-2 provides bounding boxes that define the spatial coordinates of detected items.
Understanding bounding boxes is straightforward: they’re rectangular regions that surround detected objects, typically defined by coordinates that mark the top-left and bottom-right corners. The Florence-2 computer vision model can generate these boxes for multiple objects simultaneously, labeling each with the appropriate class.
The practical applications span numerous industries. In security and surveillance, object detection identifies people, vehicles, or suspicious items in camera feeds. Manufacturing facilities use it for quality control—detecting defects, missing components, or incorrectly positioned parts on assembly lines. Retail environments leverage object detection for checkout-free shopping experiences, inventory monitoring, and customer behavior analysis.
Smart cameras equipped with Florence-2 can operate independently without constant cloud connectivity. A traffic monitoring system, for instance, can detect and classify vehicles, pedestrians, and cyclists in real-time, making instant decisions about traffic light timing or alerting authorities to accidents—all processed locally at the edge.
What distinguishes Florence-2 object detection from standalone detection models is the ability to combine it seamlessly with other vision tasks. You might detect objects in a frame, then use visual grounding to answer specific questions about those objects, or apply segmentation to get precise boundaries rather than just boxes. This interoperability happens within a single model inference, making the pipeline cleaner and more efficient.
Computer Vision Solution Matrix
Deployment scenarios and operational ROI for real-time object detection systems.
| Detection Scenario | Specific Use Case | Core Business Benefit |
|---|---|---|
| Retail Environment | Real-time product recognition and planogram compliance on shelving units. | Automated Inventory |
| Manufacturing | Sub-millimeter defect detection on high-speed assembly lines. | Real-time QC |
| Security Systems | Multi-object person and vehicle identification across perimeter zones. | Enhanced Safety |
| Autonomous Vehicles | Low-latency pedestrian and dynamic obstacle detection for path planning. | Collision Avoidance |
Describing Scenes and Content Labels
Florence-2 image captioning transforms visual information into descriptive text, making images accessible and searchable. This capability serves multiple important functions across different domains, from accessibility features to content management systems.
For users with visual impairments, image captioning is essential. When a blind person navigates a website or social media feed, screen readers can vocalize the captions generated by the Florence-2 computer vision model, providing context about images they cannot see. This isn’t just about compliance with accessibility standards—it’s about creating inclusive digital experiences.
Content creators and digital asset managers face the challenge of organizing thousands or millions of images. Manual tagging is time-consuming and inconsistent. Florence-2 image captioning can automatically generate descriptive metadata for every image in a media library, making search and retrieval dramatically more efficient. A stock photography platform, for example, can automatically tag images with detailed descriptions: “a person working on a laptop in a modern coffee shop with natural lighting” rather than just “person” and “laptop.”
Content moderation is another critical application. Social media platforms and user-generated content sites need to identify potentially problematic images quickly. Florence-2 can generate descriptions that help flag content requiring human review, identifying scenes, objects, or activities that might violate community guidelines.
For mobile applications, image captioning enables features like automated photo organization (“beach vacation 2024,” “family dinner at home”), assisted photo editing (suggesting filters based on scene type), and social media post suggestions (auto-generating captions for uploaded photos).
The Florence-2 computer vision model generates captions that are contextually rich and coherent, going beyond simple object enumeration to capture relationships and activities within the scene. This nuanced understanding comes from the model’s vision-language architecture, which learns to connect visual patterns with descriptive language during training.

Linking Text to Specific Image Regions
Florence-2 visual grounding is the capability that connects natural language phrases to precise locations in an image. This is incredibly powerful for interactive applications and robotic systems that need to respond to verbal or textual instructions about visual elements.
Think of visual grounding as the bridge between “what someone asks about” and “where it actually is” in the visual field. If you say “show me where the red button is,” a system using Florence-2 visual grounding can highlight the exact region of the image containing that red button. This goes beyond simple object detection because it’s query-driven and context-aware.
Practical examples make this clearer. In industrial settings, a maintenance technician wearing augmented reality glasses might ask, “where is the emergency shutoff valve?” The system, powered by Florence-2, can process the camera feed, locate the valve, and overlay a visual indicator in the technician’s field of view. This hands-free, vision-based interaction improves efficiency and safety.
Retail applications use visual grounding for inventory management. A warehouse worker scanning a shelf might query, “find the product with barcode XYZ123.” The Florence-2 computer vision model locates the specific item among dozens of similar packages, highlighting it on a handheld device screen.
In robotics, visual grounding enables more natural human-robot interaction. Instead of programming exact coordinates, you can instruct a robot arm: “pick up the blue wrench” or “grab the package labeled ‘fragile.'” The robot uses visual grounding to identify the correct object, then coordinates with its motion planning system to execute the task.
The technology also enhances educational applications. Interactive learning tools can ask students to identify specific elements in diagrams or photographs, then verify their selections using visual grounding. “Point to the mitochondria in this cell diagram” becomes an interactive, visually-grounded learning experience.
What makes Florence-2 visual grounding particularly valuable is its integration with the model’s other capabilities. The same system that grounds “the red button” can also read any text on that button (OCR), describe the surrounding context (captioning), and provide precise boundaries (segmentation)—all within a unified inference pipeline.
Segmentation: Not Just Where Objects Are, But Their Exact Shape
While object detection provides bounding boxes, Florence-2 segmentation goes further by identifying the precise pixel-level boundaries of objects. This distinction is crucial for applications where shape and spatial accuracy matter.
Understanding the difference is straightforward: a bounding box is a rectangle that contains an object, potentially including significant background area. Segmentation creates a mask that follows the object’s actual contours, distinguishing every pixel that belongs to the object from those that don’t.
For robotic manipulation tasks, this precision is essential. A robot arm equipped with the Florence-2 computer vision model needs to know exactly where to grip an irregularly shaped object. Segmentation provides the detailed spatial information required to calculate optimal grasp points, avoiding obstacles and handling items safely without dropping them.
Medical imaging applications benefit from segmentation’s precision, though we’ll keep this general: identifying anatomical structures, measuring dimensions, or tracking changes over time all require pixel-level accuracy. While Florence-2 isn’t specifically designed for medical use, the underlying segmentation technology demonstrates how precise visual analysis supports critical decision-making.
Augmented reality applications rely heavily on segmentation. When you want to apply a virtual mask to someone’s face, change the color of a car in a photo, or replace the background in a video call, you need accurate segmentation. Florence-2 segmentation can identify and mask people, objects, or regions, enabling these interactive visual effects to run smoothly on consumer devices.
In agriculture and environmental monitoring, drones equipped with segmentation capabilities can identify individual plants, assess crop health, or map land features with high precision. This pixel-level detail enables accurate yield prediction, targeted treatment of diseased areas, and efficient resource allocation.
The Florence-2 computer vision model handles various segmentation tasks through its prompt-based interface. Instance segmentation (identifying individual objects separately), semantic segmentation (labeling every pixel by category), and referring segmentation (segmenting based on natural language descriptions) are all accessible through appropriate prompts, making the model remarkably versatile.
Computer Vision Task Hierarchy
A technical comparison of visual perception methods, output formats, and their specific operational utilities.
| Vision Task | Output Format | Precision Metrics | Primary Utility |
|---|---|---|---|
| Object Detection | Bounding Boxes | Rectangular spatial localization (x, y, w, h). | High-speed counting, traffic monitoring, and real-time tracking. |
| Segmentation | Pixel Masks | Exact semantic or instance-level boundaries. | Robotic surgery, autonomous driving, and professional photo editing. |
| Visual Grounding | Region Highlights | Natural language query-specific localization. | Interactive AI systems, assistive tech, and voice-command vision. |
| Image Captioning | Textual Strings | High-level semantic and relational understanding. | Automated metadata generation, accessibility tools, and SEO indexing. |
Why Running On-Device Is Becoming the Standard
The shift toward on-device vision models represents a fundamental change in how we deploy AI systems. Rather than sending images to cloud servers for processing, the Florence-2 computer vision model can run directly on smartphones, edge devices, robots, and embedded systems.
Privacy is the most compelling driver of this trend. When visual data never leaves the device, users maintain control over sensitive information. Medical devices processing patient images, security cameras monitoring private spaces, and personal apps analyzing photos all benefit from the privacy guarantee that comes with local processing. No network transmission means no interception risk, no server breaches, and no concerns about how cloud providers handle your data.
Latency is another critical factor. Cloud-based inference introduces network delays that can make real-time applications impractical. A self-driving vehicle can’t wait 200 milliseconds for a cloud server to respond about whether there’s a pedestrian in the crosswalk. An industrial robot can’t pause while images upload and results download. On-device vision models eliminate this latency, enabling split-second decision-making that safety-critical and time-sensitive applications demand.
Offline operation is increasingly important as AI systems move into environments without reliable connectivity. Agricultural equipment in remote fields, underwater drones, spacecraft, disaster response robots—all these systems need to function autonomously without internet access. Running Florence-2 locally ensures continuous operation regardless of network conditions.
Cost considerations also favor on-device deployment at scale. While cloud inference costs pennies per request, those pennies multiply quickly when you’re processing thousands or millions of images daily. A retail chain with smart cameras in hundreds of stores would face enormous cloud bills for continuous video analysis. Running the Florence-2 computer vision model locally on each camera eliminates ongoing inference costs after the initial hardware investment.
However, on-device deployment isn’t without challenges. Hardware constraints matter—mobile processors have less computational power than server GPUs, requiring model optimization techniques like quantization and pruning. Battery life becomes a concern for mobile and embedded devices, as vision processing is computationally intensive. Model size must fit within device memory limits, sometimes necessitating smaller variants with slightly reduced accuracy.
Optimization is crucial. Developers need to use frameworks like ONNX Runtime, TensorFlow Lite, or CoreML to convert models into efficient formats for specific hardware. Quantization reduces model precision from 32-bit floating point to 8-bit integers, shrinking memory footprint and accelerating inference with minimal accuracy loss. These optimizations make the on-device vision model practical even on resource-constrained devices.
Quality tradeoffs exist, particularly on lower-end hardware. A flagship smartphone might run the full Florence-2 model smoothly, while a budget device might need a smaller variant or lower image resolution. Developers must balance performance requirements against the device capabilities of their target market.
Despite these challenges, the trend is clear: on-device AI is becoming the default for privacy-sensitive, latency-critical, and offline applications. The Florence-2 computer vision model, designed with efficient architectures and available in multiple sizes, aligns perfectly with this movement toward edge intelligence.
Adapting the Model to Your Specific Data
While Florence-2 demonstrates impressive zero-shot capabilities—performing tasks without task-specific training—many real-world applications benefit from Florence-2 fine-tuning to achieve optimal performance on domain-specific data.
Zero-shot performance means the model can handle tasks “out of the box” using only prompts, without additional training. For many general-purpose applications, this is sufficient. If you need to detect common objects (people, vehicles, animals), read standard text, or caption everyday scenes, the pre-trained Florence-2 computer vision model will likely perform well immediately.
However, specialized scenarios often demand fine-tuning. Imagine you’re building a system to inspect manufactured parts for specific defects that don’t exist in general image datasets. Or you need to read text in a specialized font or language variant that wasn’t heavily represented in training data. Perhaps you’re working with domain-specific objects—medical instruments, rare wildlife species, industrial components—that require specialized recognition.
Fine-tuning involves continuing the model’s training on your custom dataset, adjusting its weights to improve performance on your specific task while retaining its general capabilities. This process doesn’t start from scratch; you’re building on the foundation of knowledge Florence-2 already possesses, which means you typically need far less training data than training a model from the ground up.
Practical examples illustrate when fine-tuning makes sense. A pharmaceutical company using computer vision to verify pill shapes and markings would fine-tune on thousands of labeled pill images, teaching the model to recognize subtle differences between similar medications. A wildlife conservation organization tracking endangered species might fine-tune on camera trap images, improving detection accuracy for specific animals in specific environments.
For OCR tasks, fine-tuning helps with unusual fonts, handwriting styles, or degraded text conditions. A company digitizing historical documents with ornate typography would benefit from Florence-2 fine-tuning on samples of those specific document types, dramatically improving transcription accuracy.
The fine-tuning process requires careful dataset preparation. You need annotated examples showing the model what correct outputs look like for your specific inputs. For object detection, this means bounding boxes around your custom objects. For segmentation, pixel-level masks. For captioning, descriptive text that matches your desired style and detail level.
Transfer learning principles apply—start with the pre-trained model, freeze most layers initially, and fine-tune only the final layers with a low learning rate. This prevents catastrophic forgetting (where the model loses its general capabilities while learning your specific task) and makes training more efficient.
Data augmentation helps stretch limited training data further. Techniques like rotation, scaling, color adjustment, and cropping create variations of your training images, helping the model generalize better to real-world conditions without requiring massive custom datasets.
When deciding between zero-shot and fine-tuned deployment, consider these factors: How different is your domain from general images? How critical is accuracy for your application? Do you have access to quality training data? What’s your timeline and budget for model development? For many applications, starting with zero-shot and fine-tuning only if needed is the pragmatic approach.
AI Model Deployment Matrix
A technical comparison of approaches based on data availability, domain specificity, and operational constraints.
| Deployment Approach | Optimal Use Case | Data Requirements | Time to Horizon |
|---|---|---|---|
| Zero-shot | General objects and common reasoning scenarios. | None Leverages pre-existing model weights. | IMMEDIATE |
| Few-shot Prompting | Specialized tasks with clear formatting requirements. | Minimal 3–10 high-quality context examples. | HOURS – DAYS |
| Fine-tuning | Domain-specific language or custom object classes. | Structured Set 100s–1,000s of labeled examples. | DAYS – WEEKS |
| Full Training | Completely novel tasks or foundational research. | Massive Scale Millions of high-fidelity labeled samples. | WEEKS – MONTHS |
Why the Model Maintains Strong Performance: The Data Foundation
The strength of any AI model ultimately traces back to its training data, and this is where the FLD-5B dataset plays a crucial role in Florence-2’s capabilities. Understanding what makes this training foundation robust helps explain why the Florence-2 computer vision model performs consistently across diverse tasks.
FLD-5B refers to the Florence Large Dataset with approximately 5 billion annotations. This isn’t just about quantity—it’s about the quality and diversity of those annotations. The dataset encompasses multiple vision tasks with unified labeling, meaning the same images have annotations for detection, segmentation, captioning, and other tasks. This multi-task annotation approach is what enables Florence-2’s ability to handle different vision tasks within a single architecture.
Scale matters in machine learning. The more diverse examples a model sees during training, the better it generalizes to new, unseen situations. With billions of annotations covering countless objects, scenes, text samples, and spatial relationships, Florence-2 develops robust visual understanding that transfers across domains. A model trained on such comprehensive data is less likely to fail on edge cases or unusual inputs.
The unification of tasks during training is equally important. Traditional computer vision systems train separate models for each task, meaning the object detection model learns nothing from caption data, and the OCR model doesn’t benefit from segmentation examples. Florence-2’s training approach shares knowledge across tasks—what it learns about identifying objects helps with segmentation, OCR benefits from understanding spatial relationships, and captioning improves from detection knowledge.
This unified training creates synergies. When Florence-2 processes an image for object detection, it’s not just applying detection-specific weights—it’s leveraging its entire visual understanding developed across all training tasks. This holistic approach often yields better performance than task-specific models, particularly in complex real-world scenarios that don’t fit neatly into single-task categories.
Data quality extends beyond annotations to include image diversity. The training set needs to represent different lighting conditions, viewing angles, resolutions, and visual contexts. Indoor and outdoor scenes, professional photography and casual snapshots, clean images and degraded ones—this variety ensures the model performs reliably regardless of input quality or conditions.
Microsoft’s investment in creating and curating the FLD-5B dataset reflects a commitment to building foundation models that serve as reliable bases for downstream applications. Rather than creating narrow, task-specific systems, this approach produces versatile models that developers can deploy across various use cases with confidence.
The implications for practitioners are significant. When you deploy Florence-2, you’re not just getting a trained model—you’re inheriting the benefits of that massive, carefully constructed training foundation. This means better out-of-the-box performance, stronger generalization to your specific domain, and more robust handling of challenging inputs.
As computer vision continues evolving, the trend toward larger, more diverse training datasets will likely continue. The Florence-2 computer vision model represents the current state of this evolution, demonstrating how comprehensive training data enables truly versatile AI systems.

Bringing It All Together
The Florence-2 computer vision model represents a convergence of several important trends in AI: unified multi-task architectures, on-device deployment, prompt-based interfaces, and foundation model approaches. Whether you’re building robotics systems, mobile applications, edge devices, or interactive experiences, Florence-2 offers a compelling combination of versatility, efficiency, and performance.
For developers and teams evaluating vision solutions, Florence-2’s all-in-one approach simplifies architecture decisions. Instead of integrating multiple specialized models and managing their interactions, you can deploy a single model that handles detection, OCR, captioning, grounding, and segmentation through consistent prompt interfaces. This simplification reduces development time, minimizes integration challenges, and streamlines maintenance.
The model’s adaptability—from zero-shot deployment to domain-specific fine-tuning—means it scales from rapid prototyping to production deployment across different complexity levels. Start with out-of-the-box capabilities to validate your concept, then optimize and fine-tune as you move toward production if your specific use case demands it.
Privacy-conscious applications particularly benefit from Florence-2’s suitability for on-device deployment. As regulations around data privacy tighten and users become more aware of how their information is processed, the ability to perform sophisticated visual analysis entirely locally becomes a significant competitive advantage.
Looking forward, vision foundation models like Florence-2 will likely become standard components in AI-powered systems, much like how pre-trained language models have become ubiquitous in natural language processing. The paradigm shift from task-specific models to versatile foundation models is transforming how we build intelligent systems.
If you’re interested in diving deeper into computer vision, exploring practical implementations, or staying current with AI developments, you’ll find comprehensive guides, tutorials, and analysis at www.aiinovationhub.com. The site covers everything from model comparisons and deployment strategies to hands-on coding examples and industry applications, helping you navigate the rapidly evolving AI landscape with clarity and confidence.
The future of computer vision is unified, efficient, and increasingly accessible—and Florence-2 is helping define what that future looks like.
If Florence-2 gives apps “eyes” offline, the next step is giving your product a UI people actually enjoy using. That’s where Uizard shines: it turns sketches or screenshots into clean, editable UI/UX in minutes—perfect for fast MVPs and redesigns. Quick breakdown here: https://aiinnovationhub.shop/uizard-ai-ui-ux-generator/
Discover more from AI Innovation Hub
Subscribe to get the latest posts sent to your email.